Introduction to Cyber Threat Intelligence Course

Foreword
Welcome to a preview of something I’ve been quietly building behind the scenes: a hands-on, research-driven course titled "Threat Intel: From Forums to Frontlines."
This course is designed to teach you how to gather actionable cyber threat intelligence from underground hacking forums, specifically, posts that offer initial access to Canadian businesses. Whether you're a curious learner, a threat analyst, or someone trying to make sense of how cybercrime operates in the shadows, this course will give you a practical lens into the world of Initial Access Brokers (IABs) and real-world threat detection.
It’s not just theory. You’ll be scraping simulated dark web forums, analyzing posts, and using AI models to detect potential threats, hands-on, end-to-end. In fact this article is more like a breakthrough for that course.
Accessibility matters to me. That’s why this course will be available in five languages, English, French, German, Portuguese, and Spanish, so people from different regions and backgrounds can follow along without barriers.
This project grew out of my own exploration and curiosity. Over the past few months, I've built several tools around AI, vulnerability scanners, and now, data scrapers. One of them, Zerodayf (ZeroDay Factory), provides context-aware vulnerability analysis for web apps. That same spirit of problem-solving and experimentation fuels this course.
The course will be hosted on a Canadian cybersecurity platform I'm building called Cyber Mounties (cyberm.ca). The goal is simple but ambitious: to fill in the gaps I see in today’s cyber training, especially when it comes to practical, mission-ready skills.
This is one of the ways I want to give back to my country, and to anyone out there who wants to be part of the solution. Just like with Mission Cyber Sentinel, where my team and I uncovered vulnerabilities in software powering over 250,000 websites, Cyber Mounties has a clear mission: to protect, empower, and prepare.
The course and the Cyber Mounties platform (including its subdomains) are on track to launch by the end of May or June this year. If you would like, you could contribute by reviewing translations for accuracy.
Overview of this article
This article is more of an intro to the real course, in this article, I will go through all of the following:
- Building a Tor site with Flask & SQLite
- Building a Tor proxy with torrc & Docker
- Building a web scraper that scraps an entire site & returns a JSON containing all posts
- Prompting an existing AI model for identifying posts selling initial access
What can you do with the skills you gain?
The skills you develop will empower you to detect and understand cyber threats. If, during your research or scans (always conducted within the bounds of the law), you come across information on hacking forums that could be valuable to your government or a targeted organization, consider reporting it through appropriate channels.
Large corporations often scrape this kind of threat intelligence at scale. However, they typically sell access to that data, and they’re unlikely to notify, say, your local bakery if its RDP credentials are being sold online, especially if that bakery isn’t a paying customer. While some independent researchers do try to alert victims, the sheer volume and diversity of threats make this difficult. There are threats in countless languages across forums, Discord servers, Telegram groups, adult sites, and more.
For instance, who is actively scanning Iranian forums or Pashto/Dari-speaking Telegram channels for threats?
Not many. In fact, I previously shared some TTPs (tactics, techniques, and procedures) from a group that communicated in Pashto/Dari, highlighting just how under-monitored these spaces are.
This is where your skills can truly make a difference. By using your knowledge, you can support your country’s cybersecurity efforts, and, in doing so, help protect the broader global digital ecosystem.
This is why we need diversity in infosec because not all threats use English as their main language and even if they do, people talk in different ways and use specific terms and lingo that you can't just learn by taking a Persian language course at West Point.
If you're looking to connect with others in the field, consider joining the DFIR (Digital Forensics and Incident Response) Discord server. It’s a place where you can engage with real law enforcement professionals, cyber forensic investigators, and threat hunters like yourself:
DFIR Discord Server - Beginner's Guide
Note: The DFIR server does require some form of verification. I’m not a member myself and am not promoting it, but from everything I’ve seen, it appears to be a legitimate community.
Many of us in the hacking and cybersecurity space want to contribute meaningfully to our communities and bolster overall cyber resilience. But when it comes to reporting threats, always go through official channels or connect with verified professionals, like those on DFIR server.
Initial access brokers
Initial Access Brokers (IABs) are cyber criminals who specialize in obtaining and selling unauthorized access to compromised computer networks, typically belonging to businesses or organizations.
They act as intermediaries in the cybercrime ecosystem, supplying other threat actors, such as ransomware operators, data thieves, or corporate espionage agents, with a foothold into target environments.
Have a look here for some example posts:
https://outpost24.com/blog/use-of-initial-access-brokers-by-ransomware-groups/
What they do
- Network Compromise: IABs use various techniques to infiltrate networks. Common methods include exploiting vulnerabilities, phishing, brute-force attacks on remote desktop protocol (RDP) servers, and credential stuffing
- Persistence Establishment: Once inside, they often ensure long-term access by creating new user accounts, installing remote access tools, or embedding backdoors.
- Access Monetization: Rather than using the access themselves, IABs list and sell it on dark web forums and marketplaces. The value depends on factors like company size, industry, geography, and privilege level of the access.
- Collaboration with Other Threat Actors: Many ransomware groups rely on IABs to supply entry points into victim networks, allowing them to focus on encryption and extortion rather than infiltration.
IABs play a crucial role in the division of labor within the cybercrime underground, acting as the first step in many major cyberattacks.
What type of Access do they sell?
Initial Access Brokers offer a range of access types, depending on how deeply they have penetrated the target environment and the intended use by the buyer. The level of privilege and method of access both influence the value and utility of the listing.
Privilege Levels: Access can vary from low-privileged user accounts to highly privileged administrator or domain-level access. High-privilege access is significantly more valuable as it allows broader control over the network.
Access Methods:
- RDP Credentials: One of the most common forms of access, allowing remote desktop connections directly into the target system.
- VPS Access: Credentials to a compromised Virtual Private Server, which may already be acting as a Command and Control (C2) hub with deployed agents inside the organization’s network.
- SSH Access: Secure Shell access, typically to Linux-based systems, providing a command-line interface for executing commands and scripts.
- VPN Credentials: Login details for corporate VPNs, which may include multi-factor authentication bypass techniques.
- Web Panel or Email Access: Includes admin panels, webmail, or OWA (Outlook Web Access), which can be used for internal phishing or data exfiltration.
The nature of access is usually described in detail in the listing, sometimes with screenshots or proofs of compromise, to attract specific buyers such as ransomware affiliates, data harvesters, or espionage actors.
How Initial Access Brokers Are Utilized by Ransomware Gangs
Ransomware gangs heavily rely on Initial Access Brokers (IABs) to streamline and scale their operations. Rather than spending time and resources breaching networks themselves, these groups purchase pre-established access from IABs, allowing them to focus solely on the deployment and monetization of ransomware payloads.
Division of Labor
The cybercrime ecosystem operates with a high level of specialization. IABs serve as the entry point, while ransomware gangs handle encryption, extortion, and ransom negotiation. This division allows each group to maximize efficiency and profit by focusing on their area of expertise.
Time-to-Attack Reduction
By outsourcing the initial breach, ransomware operators can launch attacks much faster. Once they purchase access from an IAB, they can deploy ransomware within hours or days, depending on the level of access and their operational readiness. This significantly shortens the time between compromise and ransom demand.
Scale and Reach
IABs often maintain inventories of access to dozens or even hundreds of organizations, sometimes across multiple sectors and countries. Ransomware gangs can choose targets based on criteria like industry, revenue size, or geographic location, allowing for more strategic and profitable operations.
Case Example: Conti Group
The now-defunct Conti ransomware group is a prime example of this collaboration. Conti leveraged access purchased from IABs to breach a large number of organizations in a short span of time. This allowed them to maintain a high tempo of attacks without bottlenecks caused by the initial compromise phase. In leaked chat logs from Conti’s internal communications, it became clear that they actively worked with IABs and prioritized targets based on the quality and level of access being offered.
Strategic Advantage
Utilizing IABs gives ransomware gangs:
- Immediate access to internal systems
- Reduced risk of detection during infiltration
- Broader targeting capabilities
- Faster monetization cycles
This business-like model is one of the key reasons why ransomware-as-a-service (RaaS) operations have been able to scale globally and remain resilient even as law enforcement and cybersecurity efforts intensify.
How Do We Monitor Initial Access Brokers?
Monitoring Initial Access Brokers (IABs) begins by focusing on the online spaces where they operate, primarily dark web forums and marketplaces where they advertise and negotiate access deals.
In this article, you’ll learn how to identify and monitor these activities by scraping posts from a simulated Tor-based hacking forum and analyzing them using an AI model (Claude) to detect discussions related to initial access sales.
While this guide provides an introductory overview, the techniques covered are both transferable and scale-able, laying the groundwork for broader threat intelligence efforts targeting IAB activity.
Building a TOR site with Flask & SQLite
Building a TOR site is no different than creating any other website, the stack is almost the same. I haven't run any large scale site on the darkweb so I don't know if there will be other complexities down the road but from what I have seen, creating Tor sites all comes down to how your website is served, with Tor, you just have to connect to the tor network and serve your site.
Here is the source code for a Tor forum:
https://github.com/0xHamy/tor_forum
This is a fully documented site so we don't have to go through technicalities in this blog. If you follow the instructions on that Github repository, you can get your own site up & running in under 15 minutes.
The tor forum uses gunicorn to serve the site but that's not usually how it's done in the production, in production you would need threads, workers and a proper server like Apache or Nginx but for simplicity, I won't bother you with setting up a whole server today.
Though for my own website, this was the case, I had to use gunicorn, apache, cloudflare and configure all of them manually but it's a little out of scope here, those topics are strictly DevOps.
Basics of data scraping
Some of you might be familiar with data scraping from websites, if not let me refresh your memory by reminding you of Cambridge Analytics Facebook scandal.
Data gathering from sites without permission is most of the times illegal depending on your jurisdiction. In my country (Canada), it's illegal for us to scrape data from cyber-criminal sites and the firms like eSentire that do it follow specific frameworks.
There are criminal sites on the clearnet, the Tor network (dark web) and also the I2P network (eepsites). Scraping almost all of them require permission and even criminal sites have terms of service and anti-bot protection to counter data scrapers.
Some of you might think that scraping data from the Tor network might be hardest because obviously there are a few things about Tor:
- It feels different than the clear net
- It's a bit slow
- Connecting to TOR could be intimidating to some because you need a specific browser
But let me clarify before we get too deep into details, scraping data from TOR is actually easier, it's slow but grabbing data from specific parts of a website is much easier than you would do in the clearnet.
If you don't know already, most websites on the clearnet use JavaScript and it's usually blocked in most Tor sites because it can be used for tracking, fingerprinting and XSS attacks among many other things.
Scraping data from JavaScript sites
Websites that use JavaScript are more difficult to scrape data from, because the data is loaded into DOM using APIs, these API calls are made through JavaScript and they fetch data from the backend and display it on the front-end.
I have a lot of experiencing developing web apps so I have created websites that used JavaScript to dynamically update site data. The following code is an example:
https://github.com/0xHamy/zerodayf/blob/main/app/templates/manage_api.html
If you run zerodayf and open /manage-api page and view its source code, it will be empty. You see, to grab data from pages, you need to pro-grammatically get the source code of pages and then grab the data relevant to your task. But what if you can't see anything?
Here is the web page when I open it, I can clearly see data here: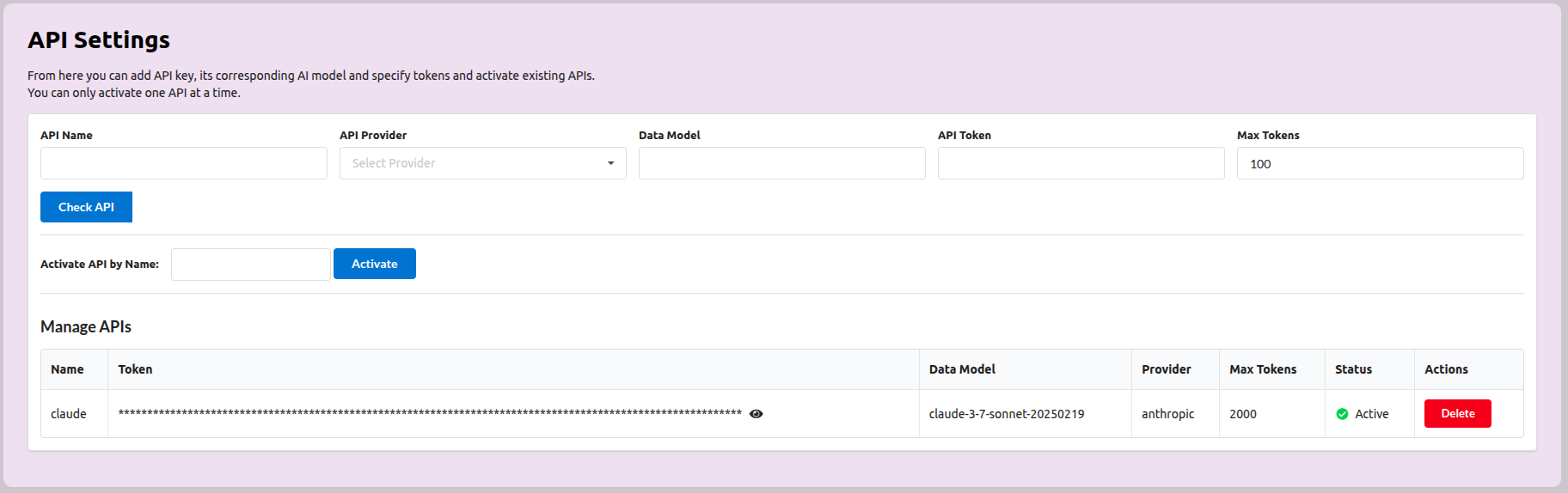
But here is the source code and it's empty: 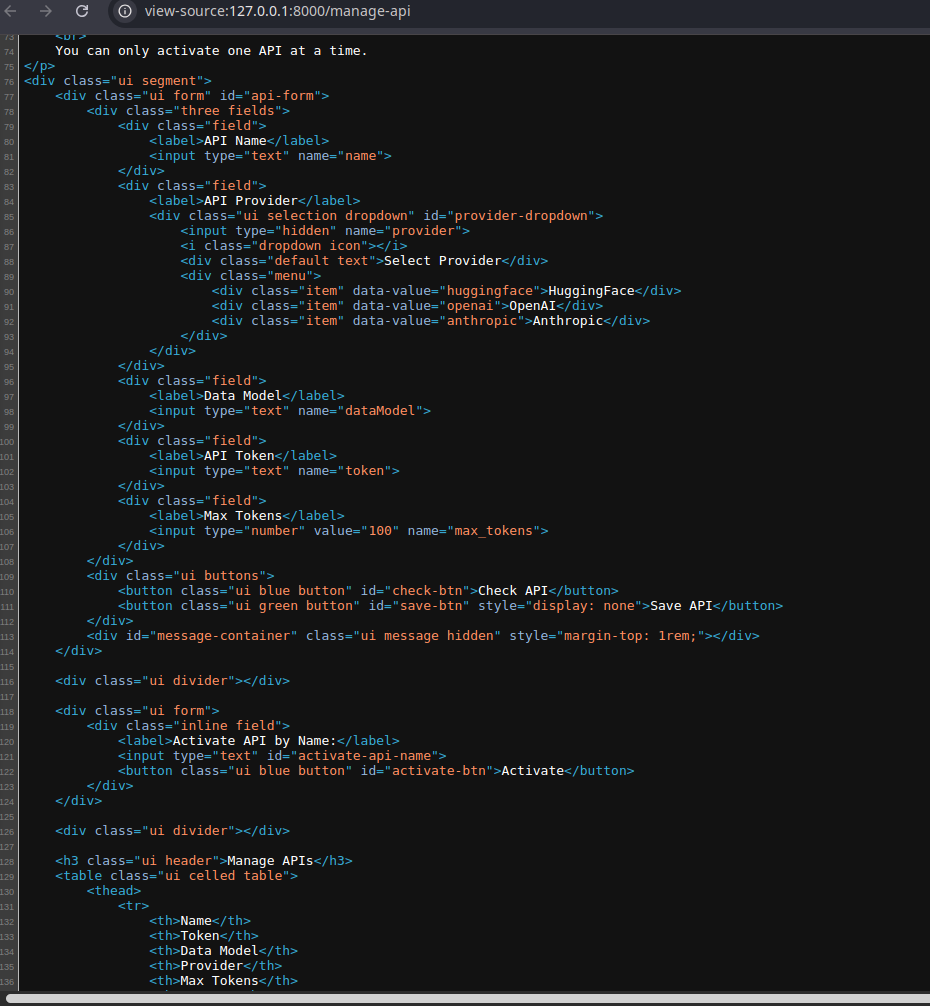
That's because data is loaded into the page dynamically using JavaScript. Here is a function from `manage_api.js` source file:
async function loadAPIs() {
/** Fetches and renders the list of APIs into the table. */
try {
const response = await fetch('/api/get-apis');
const apis = await response.json();
const rows = apis.map(api => {
const masked = '*'.repeat(api.token.length);
return `
<tr>
<td>${api.name}</td>
<td>
<span
id="token-span-${api.id}"
data-is-masked="true"
>
${masked}
</span>
<i
class="eye icon"
style="cursor: pointer; margin-left:5px;"
onclick="toggleToken(${api.id}, '${api.token}')"
></i>
</td>
<td>${api.model || ''}</td>
<td>${api.provider}</td>
<td>${api.max_tokens}</td>
<td>
${api.is_active
? '<i class="green check circle icon"></i> Active'
: '<i class="grey times circle icon"></i> Inactive'
}
</td>
<td>
<button class="ui small red button" onclick="deleteAPI(${api.id})">Delete</button>
</td>
</tr>
`;
}).join('');
$('#api-table').html(
rows.length ?
rows :
'<tr><td colspan="6" class="center aligned">No APIs found</td></tr>'
);
} catch (error) {
showMessage('Error loading APIs', 'negative');
}
}
This function makes a call to a backend function called /api/get-apis, the backend returns data when someone sends it a GET request. The data returned is then concatenated inside a HTML code and displayed.
There are solutions to scraping data from dynamically updated sites, you could use selenium, electron, playwright or puppeteer, I would suggest playwright and it's also part of the main course. But the good thing is that you may not need it at all because darkweb sites don't use JavaScript. However, my course will prepare you to scrape from any site, no matter what technology it uses.
How does this make scraping data from TOR easier?
Well, TOR won't have this complexity at all because JavaScript is banned almost everywhere, most of the web designs you see on the darkweb are purely HTML & CSS.
You won't be dealing with complex DOM manipulation performed by the sites you will be targeting so data is always going to be inside the source code and you can grab it with tools like BeautifulSoup because source code of almost all websites are in HTML.
Here is an example of source code with data: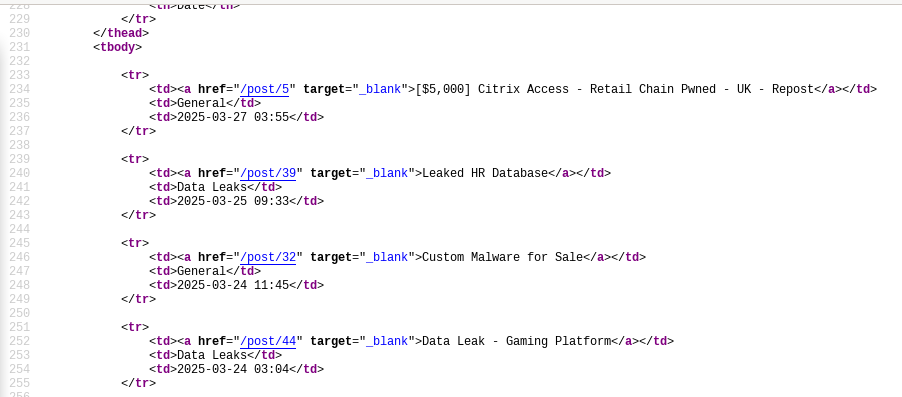
There are some problems you could face with Tor such as solving custom captchas, encrypted HTML code or slow connection when using TOR but grabbing data itself is easy.
Building a TOR proxy
Earlier, I mentioned that connecting to the Tor network might seem intimidating because most people associate it with a special browser (like the Tor Browser). But the truth is, connecting to Tor doesn't require the Tor Browser itself, you just need to route your traffic through the Tor network.
For this guide, we’ll use a basic Tor proxy using Docker. This proxy will act as a SOCKS5 endpoint that relays all your traffic through the Tor network. Once connected, you can access any .onion site as well as regular websites (though some clearnet sites may block Tor exit nodes).
This is an introductory setup using a single proxy. In the full course, we’ll scale this by deploying multiple proxies to scrape larger forums.
We won’t be turning your computer into a Tor *relay* or *node* in the network (which involves different responsibilities and setup). Instead, you’ll just be using Tor as a client to anonymize and tunnel your traffic. If you’d prefer not to run this on your local machine, you can deploy the Docker container on a VPS, Amazon AWS offers a free tier that’s perfect for getting started.
To make things easier, here’s a pre-built Tor proxy setup:
https://github.com/0xHamy/tor_proxy_gen
Like all of my projects, this repository is also well documented. You can get this up and running in under 15 minutes.
Building a web scraper
The scraper we’ll build in this tutorial is intentionally simple, designed to give you a clear, no-friction introduction to the basics of web scraping. What makes it easy is that we’ll only grab data once, from a static snapshot of the site.
But in the real world, things are rarely that straightforward.
Imagine a site that’s been live since February 4th, 2023. How do you reliably scrape every post from that date up to today, without missing the ones being published right now as your scan runs? What about posts that are added after your scraper finishes?
That’s where tiered scanning comes in. In the full course, we’ll deal with a more realistic environment, one where the site continuously updates itself via a script (similar to populate.py) that writes fresh data into the database every few hours, simulating an active dark web forum.
Extracting data from a single page is easy, and you’ll learn how to do that here. But scaling that process is a different beast. In the real course, we’ll tackle the tougher problems:
- Handling large datasets
- Designing scrapers that scale
- Bypassing CAPTCHAs
- Generating and rotating proxies
- Dealing with anti-bot protections
- Translating data (e.g. from Russian to English)
In this tutorial, we’ll focus on scraping a specific category of the site, /marketplace/sellers, where users post ads to sell their products or services. Your first task: enumerate every post from that page. It’s a small but real-world scenario that mirrors how threat intel gathering actually begins.
How do we do that?
- Launch the simulated tor forum
- Examine source code of /marketplace/sellers
- Detect links or URI endpoints for all posts; there is probably a pattern for it
- Open every post and gets its content; to do this you must analyze source code of a post to see where the content is and how to target it
- Copy paste the entire portion of post listings to your favorite AI model and ask it to write a scraper for you to extract all posts along with timestamp and its category
- The final data should be in JSON format so that it can easily be passed to another program
- Make the program more modular so that it's reusable across different environments; it should work as a standalone script and it must be easier to be imported and used as part of another program
Prompt your AI-buddy first, and then compare your final solution to mine:
https://github.com/0xHamy/minimal_scraper/blob/main/app/services/scraper.py
Data scraping web interface
As you can see, the process of creating the scraper is straightforward, but we have also created a web interface to easily interact with the data scraper, save data to databases for later access, filter tables and search them, view data and delete them.
All of these things are just basic web development to make usage of a program easier. These are not really things that we should spend our time on but at least now you know that the scraper.py is a core part of the program.
The web interface is just there to provide a good user experience.
Fine-Tuning LLMs vs. Using Existing AI Solutions
When working with large language models (LLMs) to identify specific types of content, such as posts that match a certain theme or intent, you generally have two main options: fine-tuning a custom model or leveraging an existing LLM through an API.
APIs cost money but it's cheaper and easier to use. Fine-tuning requires data and time and you may not have it.
To get started with classification, a simple yet effective approach is labeling posts as positive, neutral, or negative based on the intent or context of the content. This helps build a training or evaluation dataset that can be used for either approach.
You can view sample labeled data I created here:
https://github.com/0xHamy/minimal_scraper/tree/main/datasets
Understanding the Labels
- Positive Posts: These directly involve the sale of unauthorized access to a company (e.g., "Initial access to RBC Bank available").
- Neutral Posts: These are often general advertisements, like selling tools, generic exploits, or malware that don't directly implicate a specific organization.
- Negative Posts: These include off-topic discussions or unrelated services, such as hosting, spam tools, or VPS sales without specific targeting.
A key distinction to keep in mind: not all RDP access sales are equal. A generic RDP to a random system isn’t the same as RDP access to a large enterprise like a bank. The former may be nothing; the latter is a clear signal of IAB activity.
Fine-Tuning vs. Using Pre-Trained Models
Fine-Tuning: You can fine-tune an LLM like LLaMA, Falcon, or GPT-J on your labeled dataset to build a specialized classifier. This gives you control, but it requires infrastructure, compute, and more data than you might think to reach acceptable accuracy.
Using an Existing LLM (via API): A faster and cost-effective alternative is to use an existing LLM API to classify content dynamically. This doesn't require retraining the model and can give surprisingly accurate results with good prompt engineering.
Example: Claude Sonnet API
To demonstrate, I’ve integrated Claude Sonnet's API into my scraper to classify posts on the fly. The code module that handles this can be found here:
https://github.com/0xHamy/minimal_scraper/blob/main/app/services/claude.py
You can use this module independently to run quick tests or to batch-process scraped posts without needing to train a model yourself.
This hybrid approach, starting with an existing LLM and gradually moving toward fine-tuning, is ideal for threat intelligence work, where labeled data may be sparse or evolving rapidly.
Tutorial
I have prepared a video tutorial to get you started with all of these:
- Starting a tor site
- Creating a tor proxy
- Scraping data from the tor site
- Classifying data with Claude
In under 4 minutes, you will learn everything you need to know:
Conclusion
If you’ve made it this far without skipping the earlier sections, congratulations. That’s a solid sign you might be ready for the full course, where we go much deeper into the technical, practical, and investigative aspects of cyber threat monitoring.
There are countless threat hunting courses out there, many of them expensive, and yet most leave you without a usable tool or a clear sense of how to apply your knowledge to real-world problems.
This course takes a different approach. I teach from experience and passion, with the goal of helping you build something tangible that can genuinely support businesses and communities.
One of the biggest takeaways here is real problem solving, I am not teaching math. You’ve probably seen tutorials or YouTube videos where someone writes line after line of code without solving an actual problem. But true learning happens when you get your hands dirty, when you face real decisions, make mistakes, and figure out how to fix them.
Here are a few challenges you can try right now:
- The scraper currently uses SQLite as its database, can you swap it out for MongoDB?
- The scraper's UI is built with DaisyUI, can you refactor it using Tailwind, Semantic UI, Bootstrap, or Bulma?
- The scraper's backend runs on FastAPI, can you reimplement the same functionality using Flask, Django, Ruby on Rails, or Laravel?
This is a deliberately simple project, but if you can customize even a small part of it, you're already well on your way. Also, feel free to use AI tools to assist you, but avoid "vibe-coding" Try to actually understand what’s happening under the hood.
Best of luck, and I hope to see you in the real course.
Posted on: April 25, 2025 01:14 AM